La segmentazione semantica dell’immagine corrisponde al categorizzare ogni pixel presente in una immagine e assegnargli una etichetta significativa come “strada”, “cielo”, “persona” o “cane”. Questo tipo di tecnologia può essere utilizzato in molti modi.
Una recente applicazione nel mondo degli smartphone è la modalità ritratto sugli ultimi dispositivi Pixel 2 di Google. Qui la segmentazione viene utilizzata per aiutare a separare gli oggetti in primo piano dallo sfondo dell’immagine.
Questo tipo di etichettatura precisa dei pixel richiede una maggiore precisione nella localizzazione dei pixel rispetto ad altre tecnologie di riconoscimento degli oggetti, ma può anche fornire risultati di qualità più elevata. La buona notizia è che Google ha ora rilasciato il suo ultimo modello di analisi, DeepLab-v3 +, come Open Source, rendendolo disponibile a tutti gli sviluppatori che potrebbero volerlo utilizzare nelle proprie applicazioni.
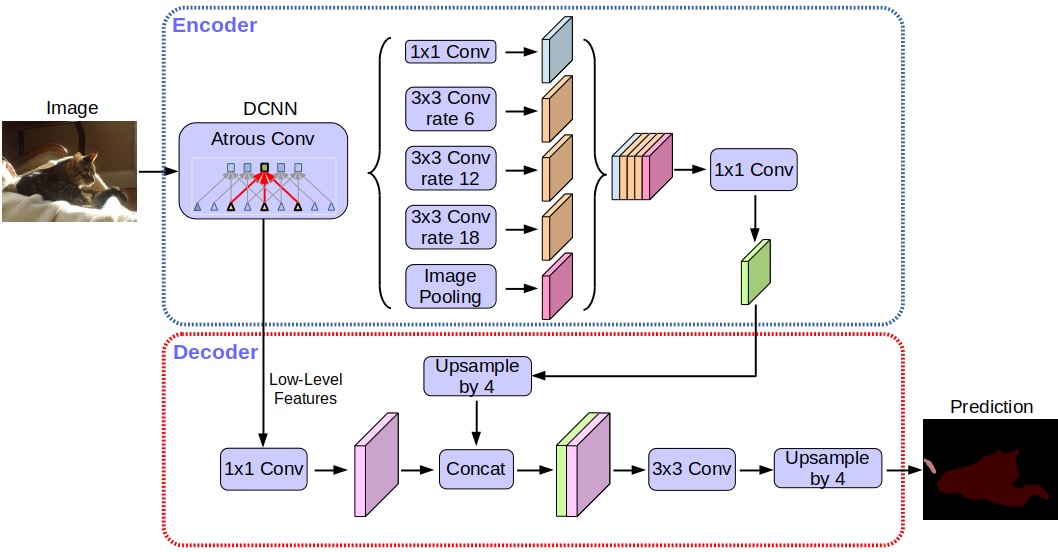

“I moderni sistemi di segmentazione dell’immagine semantica costruiti su reti neurali convoluzionali (CNN) hanno raggiunto livelli di accuratezza difficili da immaginare anche solo fino cinque anni fa, grazie ai progressi nei metodi, nell’hardware e nei set di dati”, commenta Google. “Speriamo che condividendo pubblicamente il nostro sistema con la comunità sia più facile per altri gruppi nel mondo accademico e industriale riprodurre e migliorare ulteriormente sistemi all’avanguardia, formare modelli su nuovi set di dati e immaginare nuove applicazioni per questa tecnologia.
Chi fosse interessato a saperne di più su DeepLab-v3 +, può visitare il blog di Google Research per ulteriori dettagli.
![CTA Natale iGuida [per Settimio] - macitynet.it](https://www.macitynet.it/wp-content/uploads/2025/12/regali-di-natale-consigli-di-macitynet.jpg "iGuide per i regali di Natale - macitynet..ti")











